In this blog post, I am going to walk through the AWS DynamoDB database and its feature. I will initially focus on features, and after that accessing AWS DynamoDB using a C# application.
I am going cover the following topics in this post:
- Firstly, I will explain what is DynamoDB
- Secondly, I will cover its key features
- Thirdly, I am going to create a DynamoDB table using the AWS Console
- And finally, I am going to access the table using .NET CORE Lambda (C#)
What is AWS DynamoDB?
- Firstly, DynamoDB is an extremely fast serverless NoSQL database.
- Secondly, it fully managed and can be set up to support multi-region active-active mode.
- Thirdly, DynamoDB supports in-memory cache for highly scalable applications. [though in-memory cache is an add-on feature and it doesn’t come by default, the AWS DynamoDB Accelerator (DSX) feature should be enabled to get the in-memory cache feature]
- Fourthly, it can support more than 10 trillion requests per day and up to 20 million requests per second.
- Fifthly, DynamoDB can support ACID transactions.
Another very important thing to mention about DynamoDB is that it uses key-value and document data models. And because of that, it supports an extremely flexible schema.
Key Concepts of AWS DynamoDB
Now let’s talk about few important concepts of DynamoDB.
Read/Write
Using Read/Write capacity we can manage the cost of DynamoDB because it charges based on Read/Write capacity. Write capacities are more expensive compare to read capacity.
We can have more readers and fewer writers to keep the cost minimal. And that’s usually how most of the applications behave the read access is usually 70% on average compare to write capacity.
Along with that, it provides an auto-scale feature to unpredictable workload as well. So we can either use a read-write capacity mode we can use an autoscale feature. A workload that can go up and come down using on-demand capacity will auto-scale instantly. The auto-scaling feature is more expensive.
When we set auto-scaling mode, we scale based on a percentage of load and then scale down and keep a consistent read-write capacity for a normal workload.
Triggers
DynamoDB supports triggers capacity using AWS Lambda functions. The feature is comparable with the traditional RDBMS databases.
When we configure trigger functionality in a DynamoDB table, it will trigger an AWS Lambda function. And the lambda function will have the data pre-change as well as post-change. And we can perform features like audit etc with the data.
Keys
In terms of keys, there are two main concepts that are very important to understand about DynamoDB. DynamoDB supports two types of keys, a partition key and a sort key as primary keys.
The partition key is what is used to create a partition on the table. And sort key is what used to sort the data inside of the partition.
Apart from the partition key and sort key, we can also create a secondary index on the table. That we can also use apart from the partition key and sort key to supporting faster search of data inside of the table.
Apart from the above-mentioned features, there is a couple of other features that are worth mentioning. The first one is that there is support for point-in-time recovery for the DynamoDB table. And second, it has support for on-demand backup and restoration of the table.
Create Table using AWS Console
Using AWS Console, you can create a DynamoDB table easily. In the top search bar, search for DynamoDB, and select it. When the DynamoDB console appears, in the dashboard, click on the Create Table button to create a new DynamoDB table.
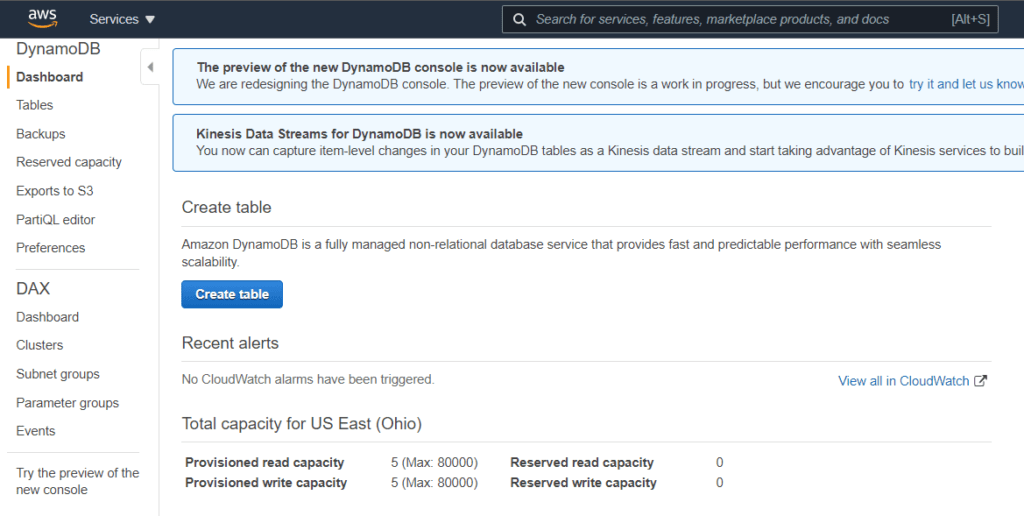
When creating the table, apart from providing the table name, you can provide partition key and sort key as well.
By default, the primary key is the partition key, but we can also add a sort key along with it.
One thing to remember, if we don’t use the sort key, then the partition key has to be unique across the table. So you have to give a unique identifier. But if you add a sort key then the partition key along with the sort key has to be unique.
For this example, I will create a new table user-table, with City as the partition key and Email as the sort key.
Use DynamoDB API in .NET Core
For accessing DynamoDB programmatically, we can use AWSSDK.DynamoDBv2 NuGet package.
Create data in AWS DynamoDB
For inserting data into the AWS DynamoDB table, we will use the class AmazonDynamoDBClient. If the service is running inside AWS it will use the IAM role assigned to the service to get access to the DynamoDB table.
The following code will create a new user record inside of the user-table DynamoDB table created.
public async Task<bool> CreateUserAsync(string city, string address, string email, string phone)
{
var client = new AmazonDynamoDBClient();
var response = await client.PutItemAsync(new PutItemRequest
{
TableName = "user-table",
Item = new Dictionary<string, AttributeValue>()
{
{ "City", new AttributeValue { S = city } },
{ "Address", new AttributeValue{S = address } },
{ "Email", new AttributeValue{S = email } },
{ "Phone", new AttributeValue{S = phone } },
}
});
return response.HttpStatusCode == System.Net.HttpStatusCode.OK;
}
Read data from AWS DynamoDB
The following code will read existing user records from the user-table DynamoDB table created. In the below example, it will perform a scan operation in the table.
public async Task<User[]> GetUsersAsync()
{
var result = await dynamoDB.ScanAsync(new ScanRequest
{
TableName = "user-table"
});
if (result != null && result.Items != null)
{
var users = new List<User>();
foreach (var item in result.Items)
{
item.TryGetValue("City", out var city);
item.TryGetValue("Address", out var address);
item.TryGetValue("Email", out var email);
item.TryGetValue("Phone", out var phone);
users.Add(new User
{
Address = address?.S,
City = city?.S,
Email = email?.S,
Phone = phone?.S
});
}
return users.ToArray();
}
return Array.Empty<User>();
}
If we want to query the table for faster access, we can use QueryAsync instead of ScanAsync. Below is how we can use the QueryAsync method to read records where email and city match the request sent to the method.
public async Task<User[]> GetUserAsync(string city, string email)
{
var request = new QueryRequest
{
TableName = "user-table",
ExpressionAttributeValues = new Dictionary<string, AttributeValue>
{
{ ":city", new AttributeValue { S = city } },
{ ":email", new AttributeValue { S = email } }
},
KeyConditionExpression = $"City = :city AND Email = :email"
};
var response = await dynamoDB.QueryAsync(request);
if (response?.Items?.Any() != true)
{
return Array.Empty<User>();
}
var users = new List<User>();
foreach (var item in response.Items)
{
item.TryGetValue("City", out var cityOut);
item.TryGetValue("Address", out var address);
item.TryGetValue("Email", out var emailOut);
item.TryGetValue("Phone", out var phone);
users.Add(new User
{
Address = address?.S,
City = cityOut?.S,
Email = emailOut?.S,
Phone = phone?.S
});
}
return users.ToArray();
}
Delete records from AWS DynamoDB
The following code will delete an existing user record from the user-table DynamoDB table created.
public async Task<bool> DeleteUserAsync(string city, string email)
{
var request = new DeleteItemRequest
{
TableName = "user-table",
Key = new Dictionary<string, AttributeValue>
{
{ ":city", new AttributeValue { S = city } },
{ ":email", new AttributeValue { S = email } }
}
};
var response = await dynamoDB.DeleteItemAsync(request);
return response.HttpStatusCode == System.Net.HttpStatusCode.OK;
}
Conclusion
As you can see from the examples above, it is extremely simple and easy to access DynamoDB table data from .NET Core code.
I captured the entire process in the following YouTube video: