In this blog post, I am going to cover the following four topics about NoSQL databases:
- What is NoSQL?
- The main differences between a NoSQL and RDBMS
- Why we should use NoSQL and where NoSQL is best suited
- How Horizontal scaling works in NoSQL
What is NoSQL?
NoSQL (also known as Non-SQL or not only SQL) is a database management system. And they do not save data in a relational data structure as other SQL-supported RDBMS do.
In my opinion, NoSQL should have been named a NoRDBMS because SQL is just a structured
query language it is not essentially a database management system. Whereas NoSQL is a database management, unlike the RDBMS or Relational Database Management System.
And NoSQL databases try to solve some of the issues which we get into while building internet-scale distributed systems using RDBMS.
And NoSQL databases do not save data in a relational data structure as other SQL-supported RDBMS do.
A succinct description of RDBMS
We cannot discuss NoSQL and why we should use NoSQL, etc without consulting RDBMS. But RDBMS is vast and I am not going to do justice writing about it in a paragraph in this blog post. So if you do not know what is RDBMS, I will strongly suggest you read about it.
RDBMS stands for Relational Database Management System and it keeps data in tables and fixed columns. Where the tables can have a relationship with each other.
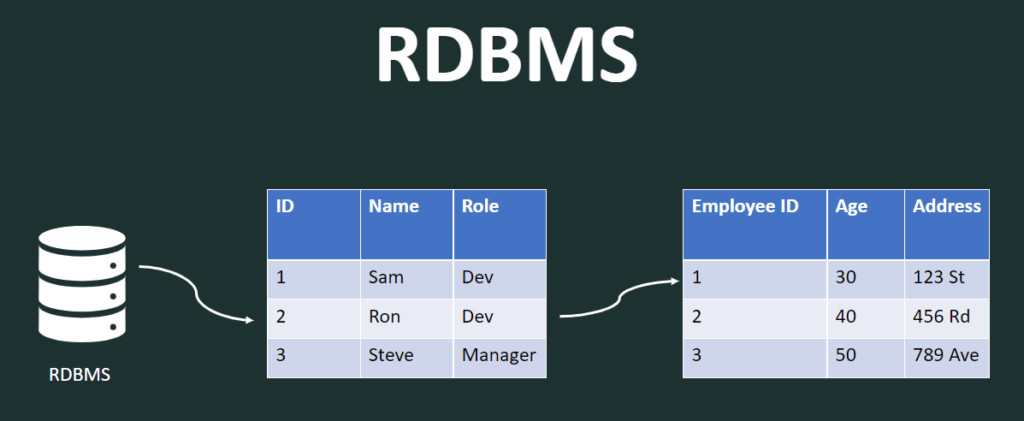
For example, here we have this employee table which has ID, Name, and Role. And then next we have the employee detail table where Employee ID, Age, and Address are the three columns.
Here the employee table and employee detail table are related to each other and they are connected through the Employee ID key. And this is the relation in the relational database.
The main underlying reason for segregating tables into multiple tables using a concept known as normalization is to save space by segregating repeated data into multiple tables.
Categories of NoSQL
At a high level, there are four categories of NoSQL databases.
- The first category of the NoSQL database is a document database. And in a document database, the data is stored in a JSON format an example of a document database is MongoDB.
- And the second category of the NoSQL database is the key-value database. As the name suggests, the data is saved in terms of key-value pairs. And an example of a key-value database is DynamoDB.
- The third category of the NoSQL database is the wide-column database. In the wide-column database, the data is stored in tables and rows. When you see tables and rows you might think about RDBMS. But the fundamental difference here is the data is stored in tables and rows in the dynamic column. That is the name and the format of the column can vary from row to row in the same table. And an example of a wide-column database can be Apache Cassandra or Azure tables.
- And the final and fourth category of a NoSQL database is a graph database. In a graph database, the data is stored in nodes and edges. And an example of a graph database is Neo4j.
All these categories are massive in themselves, and I cannot do justice coving these as a part of today’s topic so I will cover them in separate blog posts.
The difference between NoSQL and RDBMS
RDBMS
The case for why not RDBMS, especially in the case of building highly distributed systems on an internet scale.
Rigid schema
The first reason is RDBMS has a rigid schema, and why is that problem? That should not be a problem in a normal scenario. Because a rigid schema is good in a certain condition.
The main problem with rigid schema is essentially in a development methodology more
than anything else. To support the need for Agile development we need to develop an application
without spending a lot of upfront time on perfect database design. And that does not work very well with RDBMS.
I’m not saying it is not possible but it is not very convenient with RDBMS. We can change the design later, but changing the schema at a later point in time in the development cycle comes with a lot of development and performance considerations. And sometimes it makes the database complex throughout the life cycle of a project.
Storage optimization
The second reason is storage optimization is a core part of the RDBMS architecture. Storage optimization in itself is not a bad thing, in fact, it is the right strategy for a lot of situations. But RDBMS focuses a lot on storage optimization, while at times compromising speed.
And it was needed when storage price was an issue. But nowadays storage is cheap. I still remember an 8MB flash drive used to cost 20 dollars but now we can get a 1 terabyte drive at the same price. Hence storage price is not a critical consideration anymore.
And with the data space optimization, there was a lot of inherent complexity in the data model. Which has also historically introduced a lot of complexity to an application.
In fact, NoSQL got its popularity in early 2000 mainly when storage became cheap.
Scaling
The third reason is RDBMS supports only vertical scaling. If an application does not need a lot of read-write it is fine to have only vertical scaling.
But for applications that have to deal with millions and millions of reads and writes, only vertical scaling can be an issue.
NoSQL
Now let’s look into why NoSQL.
Flexible schema
First of all, NoSQL supports flexible schema, which is also the opposite of how RDBMS works.
For example, in the document data structure, we can add multiple attributes at a later stage in development.
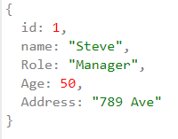
For example, the document schema above represents the same employee entity I shared in the previous RDBMS table structure. But here everything is under the single JSON document schema. The ID, Name, Role Age, and address.
And let’s say at a future point in time if we want to add email or if we want to support the email, it’s very easy just to add the email on the rest of the documents. Without worrying about losing any consistency causing any error creating null columns.
Hence having a flexible schema helps NoSQL to be a very good candidate for Agile development.
Scaling
NoSQL can scale vertically as well as horizontally. So vertical scaling which is supported by RDBMS is also supported by NoSQL. But on top of that, it supports horizontal scaling.
Meaning you can scale the server across multiple boxes. I will cover some of the details of the horizontal scaling of NoSQL in the later part of the post.
Ease of development
This particular point is very subjective. In my opinion and experience with myself and my team, I have seen it is much easier to develop in NoSQL databases compared to the RDBMS.
Since most of the NoSQL databases provide native programming language API, it is very easy to
develop using the tools provided by NoSQL.
One disclaimer here is that if someone has already learned and spent time in SQL and understands how to write an optimized query. How to create an index or performance tune a store procedure. For those individuals, RDBMS might work better.
But for a new developers, I have seen in my personal experience that they can pick up a NoSQL database extremely fast. And that is due to the less complex programming APIs, which are usually part of native programming language packages. For example, if you are working with MongoDB with .NET, you will probably use .NET API for MongoDB.
NOTE: One thing I want to make sure I mention clearly to avoid any confusion on this topic. NoSQL does not replace RDBMS. There are still a lot of scenarios where RDBMS makes sense and I personally also use RDBMS in a lot of projects. But in certain scenarios, NoSQL is a much better option and we are going to discuss a few of these scenarios here. In my opinion, they are more complementing technologies rather than competing technologies, at least at this point in time.
Where we can use the NoSQL database
Agile development environment
The first place where we can use a NoSQL database is a fast-paced Agile development environment. And the reason as I mentioned earlier is mainly due to the flexible schema.
Microservices
And the second place where we can use a NoSQL database is in highly distributed systems. Distributed systems that use multiple microservices across a distributed network.
In the case of microservice, one thing we want to do is to keep the database owned by the
microservices themselves. And this can be done very easily these days using serverless NoSQL solutions like DynamoDB in AWS, MongoDB in Atlas, and Azure table in Azure. It is easy to build microservices with a NoSQL database using serverless technology.
Heavy volumes of read-write
The third place where we can use it is where we need to support a huge volume of data. When you need to support a huge volume of data and large read-writes NoSQL is the place to go.
Scaling out
Related to the large volume of data, when you have a large volume of data it will essentially have excessive read-write into the database. In this case, scaling up has an upper limit and the only solution is to scale out horizontally. In this case, also using the NoSQL databases is a better option.
Horizontal scaling
Now let us look into horizontal scaling. Horizontal scaling is nothing but scaling the database
horizontally across multiple boxes. Basically scaling DB across multiple machines in a cluster.
The data are distributed across multiple partitions (also known as sharding), and a hash of the data is created to determine which partition a particular record will go to. Just like an index in a book.
And each partition usually has multiple replica nodes, where the database copies over the same data. NoSQL DB uses the CAP theorem, reducing consistency to provide better availability and speed.
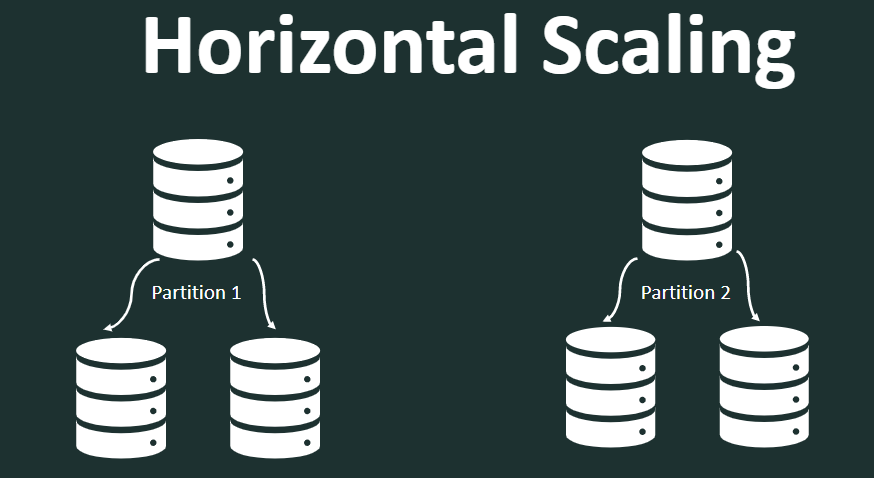
In the above example, Partition 1 has two replicas. And similarly, we can have another partition which is storing some different sets of data and has its own replica. And for each partition, the data will be copied over to the replicas.
Most NoSQL DBS are eventually consistent, so when a DB update happens within a partition, it is then replicated eventually to all the replica nodes. but this happens so fast that usually, it will not cause a read from the application not to get the data from a read replica.
One concern you might have is what this eventually means. Usually, it is in a few milliseconds and it happens so fast that you will never notice it. In my experience, I have never noticed a situation where we updated data, and then we made a get call and we did not get an updated value.
Conclusion
A lot of people are still skeptical about the NoSQL database presuming they do not support ACID property. Which is very critical for data consistency.
But that is not the case. Some of the NoSQL databases like MongoDB support ACID transactions.
One advantage of RDBMS is that all RDBMS support ANSI SQL for querying the data, so not a lot of a learning curve between multiple RDBMS databases. If you have to just read and write the data.
But for NoSQL products, on the other hand, everyone has their own API. So that causes a little bit
of a learning curve if you are moving from one NoSQL database to another. But in most cases, APIs are simple enough that you don’t have to have a lot of time. But still, I’ll consider it as a little bit of
a learning curve.
Another point I want to make is that we can scale RDBMS horizontally using a manual sharding process. I myself have implemented sharding in RDBMS especially in Postgres database in a multi-tenant environment.
And it is doable, but it takes a lot of effort to build such a system. Plus it can be really erroneous sometimes and can cause some unknown issues in a production environment. Whereas in a NoSQL database this comes out of the box. Whereas a NoSQL database supports horizontal scaling out of the box.
I converted this topic into a YouTube video here.